2023. 12. 24. 02:12ㆍAI & ML & DL/정리
일단 처음에 다뤄볼 모델은 Cox Proportional Hazard라는 모델입니다.
왜냐하면 이 모델을 기반으로 제가 산학 프로젝트를 진행했기 때문이고 주로 이 모델을 많이 사용해서 그렇습니다.
일단, 앞서 설명하기 전에 의료데이터에 대해서 알아보도록 하겠습니다.
의료데이터는 주로 time-to-event data 형식을 띄는데 우리가 주로 다루는 데이터 형식이 (X, Y)라면
time-to-event data는 (X, T, E)로 표현이 됩니다.
X(covariates)는 환자로부터 관찰된 covariate들을 말하며 아주아주 쉽게 표현하자면 그냥 우리가 아는 X랑 비슷하다고 볼 수 있습니다.
그냥 환자의 상황이나 상태 이런게 들어가지요. (정확하게 이렇게 말할 수 있는 지는 모르겠습니다...)
E(event)는 연구기간 도중에 각각 환자들에게 우리가 살펴보고자 하는 사건이 발생했는지 안 했는지의 여부입니다.
예를 들면, 췌장암의 발병을 예측하겠다고 했을때는 E는 췌장암의 발병 여부가 됩니다.
주로 0,1로 표현하며 1은 발생 했을 때, 0은 연구 기간 도중에는 발생하지 않았을 때를 의미합니다.
T(time)는 환자를 관찰한 후에 사건이 발생하기 까지의 시간을 의미합니다.
대게 time-to-event data들은 연구기간이 정해져 있으며 그 이후에는 환자들을 추적할 수 없습니다.
또한, 환자들이 전부터 사건을 이미 겪은 것도 추적할 수가 없죠.
그래서 연구기간까지 사건이 발생하지 않은 환자들의 데이터들을 right-censored data라고 하며
right-censored data를 뜻하는 T와 E가 따로 정해져 있습니다.
반대로 연구를 시작하기도 전부터 사건이 이미 발생한 환자들의 데이터들을 left-censored data라고 하며
이를 뜻하는 T와 E도 따로 정해둡니다.
(물론 제가 맡은 산학 프로젝트에서는 left-censored data가 존재하지 않아서 잘 모릅니다.
그렇지만 혼동을 피하기 위해서 left-censored data를 뜻하는 T와 E를 따로 둘 가능성이 아주 큽니다.)
그러면 이제 대략 데이터의 특징에 대해서 설명했으니 본격적으로 모델에 대해서 알아보도록 하겠습니다.
이제 time-to-event data를 주로 survival data라고도 부르는데요.
이러한 데이터를 통해서 사건이 발생하기까지 걸릴 시간을 예측하거나 분석하는 것을 Survival Analysis(생존분석)라고 합니다.
Survival Analysis를 통해서 우리가 계산하는 것은 시간 t에 대한 risk score(위험도)로 risk score는 사건이 발생할 정도를 뜻합니다.
Survival Analysis에 대해서 여러가지 방법이 있지만 저는 산학 프로젝트에서 기본이 되었던 모델, CoxPH 모델부터 설명하려고 합니다.
Cox Proportional Hazard model(콕스비례위험모델)은 Cox가 1972년에 고안한 모델로써 이러한 가정을 갖고 있는 모델입니다.
"시간에 따라서 그려지는 확률과정에 대해서 risk는 linear하게 간다!"
(좀 더 쉽게 풀면은... "시간에 따라서 risk score도 linear하게 진행된다." 이 정도로 해석할 수 있을 것 같습니다.)
이러한 가정을 보고 Proportional assumption 혹은 Cox assumption이라고 합니다.
좀 아주아주 쉽게 생각해보도록 하겠습니다. 인간은 나이가 많아질수록 주로 병에 더욱 취약해지죠?
그래서 저희는 나이가 많아질수록 risk는 점진적으로 늘어간다고 생각할 수 있습니다.
이런 접근이 Cox assumption입니다.
(정확히는 아닐 것 같지만 아주아주 쉽게 설명하기 위해서 이렇게 표현했습니다.)
다음 모델의 계산 식입니다.
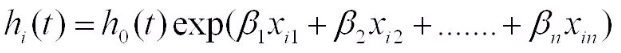
여기서 h(t)는 hazard function으로 시간 t일때 사건이 일어날 risk score를 의미하죠.
h0(t) 같은 경우는 baseline hazard로 해당 시간 t일때 사건이 기본적으로 일어날 확률을 의미하죠.
(정확히 어떻게 계산하는지는 설명을 하긴 어렵지만 제가 사용한 라이브러리에 의하면 원래 데이터로부터 추출해 내는 것으로 알고 있습니다.)
다음 x1... xp는 covariate입니다. 각각 1...p는 column 번호를 의미하죠.
옆에 붙는 b1... bp는 covariate들에 걸려있는 weight을 의미합니다.
즉, 해당 column들에 대한 영향력을 의미하죠!
주로 b1... bp는 Cox Partial likelihood를 통해서 학습할 수 있습니다. (일종의 loss function이죠!)
아래는 Cox Partial likelihood에 대한 설명입니다.
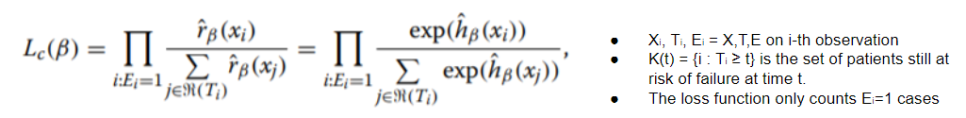
이런 모델의 장점으로는 아주 단순한 assumption을 갖고 있어도 생각보다 성능이 좋습니다.
그리고 b1...bp들이 weight인데 이를 통해서 각 변수들이 얼마나 사건 발생에 영향을 미치는지도 분석할 수 있습니다.
(절댓값이 클 수록 그만큼 영향력이 더 큰 거겠죠?)
그리고 일단 설명가능한 모델로써 의사들이 이를 보고 동의하는데도 아주 편합니다.
단점으로써는 이 assumption이 너무 단순하다는 겁니다.
non-linear하게 사건이 진행되도 linear하다는 가정때문에 못 잡아내는 것도 있고 변수들끼리 서로 섞여서
사건에 영향력이 더 커질 수 있는데 모델의 특성상으로 각각 변수들끼리 따로의 영향력을 알 수밖에 없습니다.
이러한 점 때문에 non-linear한 approach들이 생겼죠.
그 중 제가 다뤄봤던 모델들은 DeepSurv와 DeepHit이었습니다. 쟤들도 언제 시간되면 다뤄보도록 하겠습니다.
제가 아무래도 6개월동안 잠깐 살펴본 주제이기도 하고 Survival analysis에 대한 기본지식이 하나도 없이 하다 보니깐 잘못 설명한 것들도 많을 겁니다. (학부생 주제에 이렇게 깐깐해야할 주제를 지 편한대로 설명하는 것도 웃기고요 ㅎㅎ)
그래서 부족할 점이 많을 건데 혹시나 지적할게 있다면 자유롭게 지적해주시길 바랍니다 :)
이 글은 제가 아주아주 예전에(무려 2020년 대학교 3학년때!) 썼던 글인데요.
예전에 산학프로젝트로 췌장암 예측 관련해서 프로젝트 했을 때 같이 공부했던 모델이었습니다.
이 모델을 이해하는게 꽤나 어려웠던걸로는 기억하는데, 이제는 약간 가물가물하네요.
다음으로 제가 썼던 DeepSurv 관련된 글은 간단했던걸로 기억합니다. 저것도 슬슬 옮겨야겠네요.
'AI & ML & DL > 정리' 카테고리의 다른 글
| Convex function의 특징 및 왜 Binary Cross Entropy는 convex 한가? (0) | 2024.07.01 |
|---|---|
| 2024.05.14. OpenAI Spring Update 정리 (0) | 2024.05.16 |
| [MLC] 필수적으로 알아야 할 모델들 (0) | 2023.12.24 |