2023. 12. 24. 02:04ㆍAI & ML & DL/정리
전에 MLC 논문을 리뷰했을 때 MLC 문제에서 기본적으로 알아야 할 모델들에 대해서 정리하면 좋겠다곤 생각했습니다.
그래서 이번 글은 MLC 문제를 볼 때 꼭 비교대상으로 넣는 모델들에 대해서 다뤄보겠습니다.
아니 근데 MLC가 뭔데?
앞서 들어가기 전에 MLC 문제가 뭔지부터 보죠.
MLC는 multi-label classification의 줄임말로 한 data instance가 어느 label들에 속해 있는지를 보는 겁니다.
간단한 예시를 보여드릴께요. 아래 사진들은 어떤 사진처럼 보이시나요?

지금 위 사진은 각각 개, 고양이 사진으로 한 label로 정의할 수 있습니다.
각각 '개'라는 label에 속한 사진, '고양이'라는 label에 속한 사진으로 볼 수 있겠죠?
이런 문제는 single-label classification으로, 머신러닝을 할 때 주로 보는 문제 유형입니다.
Single-class classification 및 Multi-class classification 둘 다 여기에 속하죠.
(이 문제들은 워낙 유명해서 더 이상 설명하지 않겠습니다.)
그렇다면... 이제 아래 사진은 어디 label에 속할까요?
음... 둘 중 하나로 분류하기가 어렵죠?
왜냐하면 이 사진은 '개'라는 label에도 속하면서 '고양이'라는 label에도 속하기 때문이죠.
그래서 이런 경우에는 한 label로 정의 내릴수가 없습니다.
즉, 이런 문제는 전에 우리가 많이 본 single-label classification으론 못 풀죠.
이런 문제를 푸는게 multi-label classification이라고 합니다.
전 줄여서 그냥 MLC라고 하죠. (앞으로도 이렇게 쓸 겁니다.)
BR(Binary Relevance)
첫 모델은 Binary Relevance입니다.
MLC 문제는 한 data가 각각 label에 존재하는지 안 하는지를 보는 문제입니다.
그렇다면, 각 label 별로 존재하는 지, 안 하는지를 보면 편하겠죠?
이런식으로 본다면, label 별로 single-class classification을 하고 나중에 각 label 별로 예측한 것을 합치면 될 것 같지 않나요?
예를 들어 위의 개와 고양이의 사진을 '개'라는 label에 속하는지 판별하는 classifier와 '고양이'라는 label에 속하는지 판별하는 classifier를 각각 돌리면
각각 '개'라는 label에 속해있다는 결과 및 '고양이'라는 label에 속해있다는 결과가 나올 겁니다.
그렇다면 이 두 결과를 하나로 합쳐서 '개'와 '고양이' 두 label에 속해있다고 하면 MLC가 되는 거 아닐까요?
이런 생각에서 나온 모델이 Binary Relevance입니다.
대략 그림으로 나타내면 아래와 같이 나타낼 수 있겠네요.
아주 합리적인 모델처럼 보이지만, BR은 아주 큰 약점이 존재합니다.
왜냐하면 BR은 레이블들끼리 전부 독립적이라는 가정하에서 예측하기 때문이죠.
해당 모델을 잘 보면, 레이블들을 X를 활용해서면 예측합니다.
다른 레이블들끼리의 관계를 포함하지 않죠.
이게 왜 문제가 될까요?
실생활에서는 레이블들끼리 독립적인 경우가 거의 없습니다.
가령 영화의 장르를 예측할 때, 해당 영화가 스릴러라는 장르에 속하면 그 영화가 호러 영화일 가능성이 더 높겠죠? 그리고 아마... 코믹 영화일 가능성은 덜 할거구요.
이렇게 레이블들끼리 서로 영향을 주는 경우가 많습니다.
그러면 레이블들간의 관계를 어떻게 반영해줄까요?
LP(Label Powerset)
레이블들간의 관계를 반영해야하면 제일 생각하기 쉬운 모델일 것 같습니다.
BR이 레이블들을 각각 예측한다면, LP는 레이블의 전체 조합이 어떨지를 예측합니다.
좀 더 정확하게 말하면 레이블의 가능한 조합 하나를 하나의 class로 치환해서 multi-class 문제로 푸는 방법입니다.
모델 구조를 그리자면 아래와 같이 그릴 수가 있습니다.
이렇게 레이블 집합을 예측하면 레이블들 간의 관계도 전부 포함해서 예측할 수 있겠죠?
그렇지만 해당 모델에는 큰 문제점이 있습니다.
바로 space-complexity(공간복잡도)가 엄청나다는 거죠.
레이블이 d개이면, 가능한 집합의 수는 2^d개가 됩니다.
이렇게 레이블 공간의 크기에 비해 너무 exponential하게 메모리를 잡아먹어서 실제로 쓰기는 어렵습니다.
그리고 성능도 그리 좋지는 않다고 합니다.
그러면, 레이블 간의 관계를 담아내면서도 complexity도 적은 방법이 뭐가 있을까요?
그래서 사람들이 MLC에 구조적 예측방법(structural prediction)들을 적용하게 되었습니다.
레이블들의 관계를 구조적으로 쪼개어 레이블 간의 관계도 보면서 complexity도 낮추는 거죠.
CC(Classifier Chain)
이 모델을 정확히 설명하려면 확률이야기가 좀 필요합니다.
실제로 저희가 레이블간의 관계를 포함해서 예측한다고 말한다는건,
X가 주어졌을 때 레이블의 조합(Y)의 확률은 어떻게 되는지를 예측한다는 것입니다.
그렇다면, 수학식으로는 아래와 같이 표기할 수 있습니다.
레이블이 d개라면 아래와 같이도 표현할 수 있겠죠.
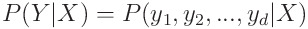
이 확률식은 정확히는 X가 주어졌을 때 y1, y2, ... , yd가 존재할 확률은 어떻게 되는가를 나타내서 확률분포로 나타낼 수가 있습니다.
이런 확률 분포를 Joint-probability distribution(결합확률분포)라고 하죠.
MLC는 레이블 공간에서 볼 수 있는 joint probability distribution을 보고 이를 최대한 비슷하게 예측할 수 있는 모델을 만드는 걸 목표로 하니 MLC의 목표는 실제 joint probability distribution에 근접하게 output을 내는 모델을 만드는 겁니다.
예를 들어, BR 은 해당 joint probability distribution에서 레이블들이 각각 독립적이라는 전제하에
marginal probability distribution들로 쪼개어 풀었습니다.
(어렵게 생각하지 마시고 그냥 두 사건이 독립이라면 P(A, B) = P(A)*P(B) 이것만 아셔도 됩니다.)
그래서 아래와 같은 식으로 풀었죠.
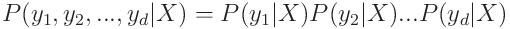
이제 CC를 설명하겠습니다.
CC는 chaining rule을 활용해서 joint probability distribution을 풀어낸 모델입니다.
Chaining rule을 쓴다면 아래와 같이 식을 쓸 수가 있습니다.
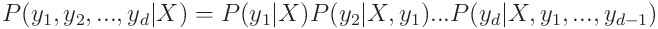
이렇게 레이블들을 예측하는 순서를 정하고
레이블을 예측할 때 전에 예측한 레이블들까지 포함시켜 예측에 활용해서
joint probability distribution에 근접하도록 예측하는 모델이 CC입니다.
모델의 구조는 아래와 같이 그릴 수 있습니다.
의외로 모델 구조는 간단하죠?
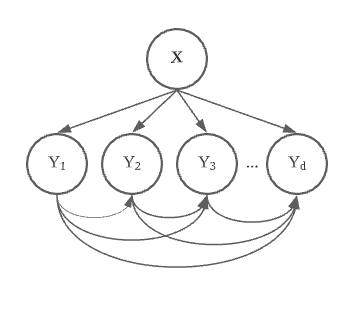
이렇게 확률적으로 다가가면서 chaining rule을 활용하는 방법론들을 chaining method라고 합니다.
그 중 대표적인 모델이 CC라서 CC를 먼저 소개드렸습니다.
CC의 매력이라면, 이론적으로 식이 예쁘게 정리될 수 있어서 설명하기도 편하고, 성능도 좋습니다.
단점으로는... 이론적으로는 레이블들 예측 순서가 성능에 영향을 안 줘야 하는데
실제로는 레이블들 예측 순서에 따라서 성능이 매우 바뀝니다.
이런 문제를 label-ordering problem이라고 합니다.
또한, 전에 예측한 레이블을 이후에 예측할 때 사용하는 것도 단점이 있는데
중간에 한 번 예측을 잘못하면, 이후에 예측할 때 잘못된 정보를 가지고 예측하다보니
Error-propagation 문제도 존재합니다.
이런 문제들을 해결하려고 시도한 방법론들도 있고
CC 구조를 RNN으로도 구현할 수 있어, 딥러닝을 적용한 방법론들도 있는데요.
나중에 시간 날 때 다뤄보도록 하겠습니다.
STA (Stacked BR)
이 방법론은 전에 예측한 레이블들을 가지고 와서 다음 예측시에 활용하는 방법입니다.
이런 방법을 stacking method라고 합니다.
이 모델에서는 BR에서 예측 한 것을 다시 feature로 원래 X랑 같이
새롭게 BR를 학습시켜 최종 예측을 하는 방법입니다.
그래서 이 모델을 Stacked BR이라고 합니다.
아래와 같이 모델을 그릴 수 있습니다.
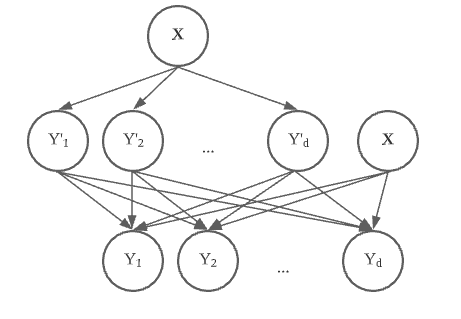
위의 모델의 장점으로는 간단하다는 점이 있습니다.
레이블 예측 순서 그런것도 고민할 필요도 없죠.
단점으로는 위 모델은 확률 식으로 풀기가 어렵습니다.
그리고 과적합 될 수 도 있다는 점도 있네요.
위 stacking method를 활용한 모델들도 좀 있습니다.
전에 다뤘던 RethinkNet 모델도 stacking method라고 생각할 수 있죠.
그외에 stacking method 활용하는 모델 중에서 제가 아는 모델은 DBR(Dependent BR)정도 있네요.
BackPropagation for Multi-Label Learning (BP-MLL)
이 모델은 위에 stacking / chaining method에 속하지 않는 방법입니다.
처음으로 MLP를 사용한 MLC 모델로, 처음으로 neural network를 활용한 방법입니다.
Loss function으로는 당시에 레이블 관계를 반영한다고 믿은 rank loss를 사용했습니다.
그렇지만 한계로는, 해당 loss function이 joint probability distribution과 관계가 그리 없다고 이후 연구에 나왔다는 점이 있겠습니다.
해당 모델은 예전에 정리해둔 게 있어서... 시간날 때 자세히 다루겠습니다.
이번에는 MLC 문제를 풀게 된다면 좀 필수적으로 보게될 모델들 위주로 설명했습니다.
BR / LP 그리고 chaining method 및 stacking method의 대표적인 모델 CC, Stacked BR, 그리고 BP-MLL까지 다뤄봤네요,
시간나면 좀 더 심화된 모델들(PCC, CNN-RNN 등)도 다뤄보겠습니다.
아주 예전에 군대 가기전에 제 블로그에 썼던 글이었습니다.
이 글은 이 블로그로 언젠가 꼭 옮길려고 했엇는데, 크리스마스 이브 기념으로 옮기게 되었네요.
네이버 블로그에서 옮기는 거라 과정이 그리 원할하지 않아서 좀 싱크같은게 안 맞을 수 있을 것 같습니다.
1차적으로 확인은 했는데 뭔가 이상한 점 있으면 지속적으로 고쳐볼게요 :)
'AI & ML & DL > 정리' 카테고리의 다른 글
| Convex function의 특징 및 왜 Binary Cross Entropy는 convex 한가? (0) | 2024.07.01 |
|---|---|
| 2024.05.14. OpenAI Spring Update 정리 (0) | 2024.05.16 |
| [의료모델] Cox Proportional Hazard 모델 (0) | 2023.12.24 |